Elvira Part 3 - Object Detection
Elvira Write-up Navigation Previous: Motor Driver Next: Reinforcement Learning
Elvira uses object detection to characterize the world around her and make decisions based on current state. This post details the computer vision object detection pipeline.
Overview
Algorithm
Results/Discussion

Blob detection in action
Overview
Elvira uses an RGB feed to detect pixels within a certain color range. It then groups these pixels based on their relative location to other groups of pixels. It tracks the centroids of these groups of pixels (aka “blobs”) and passes this information for use as the state/reward space in the reinforcement learning implementation.
Elvira’s main sensing modality is an Intel Realsense D435 RGB-D camera. This camera was selected for its robust ROS ecosystem and relative prototyping ease. Intel wrote an easy to use ROS package that was plug and play with only minor head bashing. This was useful for debugging because all the low level hardware stuff was abstracted into tidy little OpenCV arrays that were easily viewed in rqt by subscribing to the
/camera/color/image_raw ROS topic.
The main approach to the reinforcement learning algorithm is based on discretizing the RGB output array into several regions with different blobs. Certain blobs are adversarial (represent a negative reward) and friendly (represent a positive reward).This is covered in-depth in Post 4; I mention it here as motivation for the blob detection algorithm.
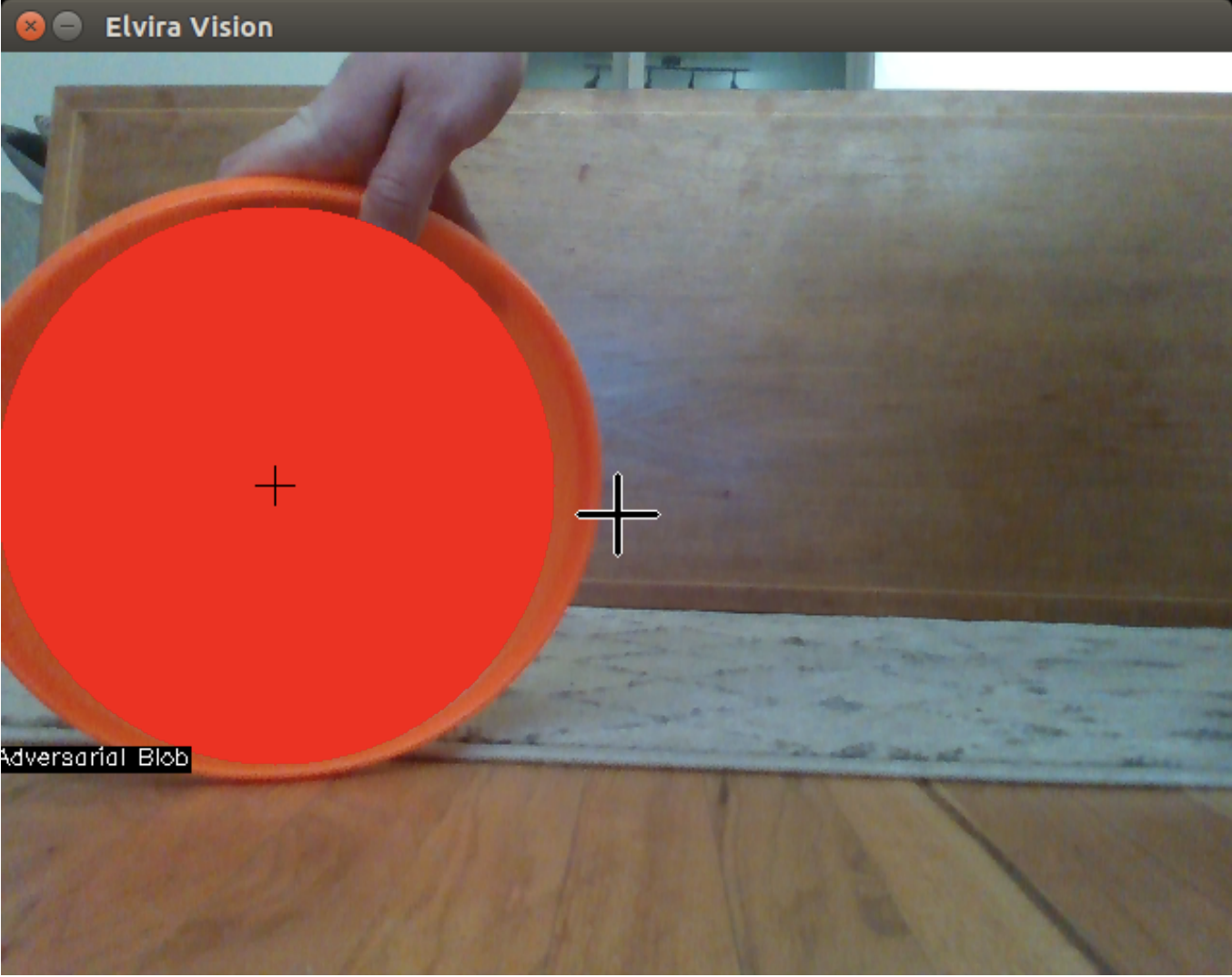
Adversarial blob; note the crosshairs indicating blob centroid and center of frame.
Algorithm Description
Algorithm is a bit of a misnomer because I took a pretty brute force approach. The object detection routine loops through all elements of an OpenCV array, checks if the pixel is of interest (by color), then creates/appends the pixel to a list of “blobs”. The actual code can be found on my Github, however I’ve included snippets below as explanatory aides.
First up, we have the wrapper code that loops through all pixels looking for a color match. The color match is via point_check(), which returns an integer used for pixel assignment. If point_check() determines that the pixel is within a specified range, pixel_assignment() is invoked to create a new blob object or append the pixel to an existing blob object. Blob objects (blobjects?) are a class I created that stores the blobs geometric primitive.
|
|
point_check() is a simple helper function that compares the color of the pixel to specified color ranges. The RGB pixel data is converted into Hue, Saturation, and Value (HSV) color space in an attempt to reduce specular effects and simplify blob detection.
|
|
Finally, we have pixel_assignment() which takes the geometry of the pixel and compares it to the centroid of all other detected blob objects. If the pixel is within some specified threshold of another blob object, it appends the pixel to the object and recalculates the object centroid. If it is outside the specified threshold, a new blob object is created.
|
|
Results/Discussion
In terms of algorithmic complexity, we let \(n\) be the number of pixels in the image frame. In reality, the image array is 2-dimensional: \(m \times k\). Accordingly, \(n = m\times k\). With this in mind, I estimate the upper bound algorithmic complexity to be \(O(n^2)\) with a more typical runtime on the order of \(O(n)\).
The main thought process behind this upper bound and “typical” runtime is based on my domain knowledge of the data input. For each frame, the algorithm will always need to scan through each pixel, however the number of blob objects will be much less than the number of pixels. The unlikely edge case that contradicts this would require the blob centroid distance threshold to be 0 pixels and the entire camera frame to pass the point_check() function. This situation is unlikely to occur in practice since we know the objects we wish to detect are larger than one pixel.
Future implementations/refinements to the object detection pipeline will focus on a few things:
1) Reducing specular effects: Colored discs (aka my roommates disc golf frisbees) were used as the objects to detect. Initially I thought the bright red, yellow, and orange frisbees would be easy to detect, but I was sorely mistaken. The frisbees were highly susceptible to lighting and rotating them in the light could greatly impact how well they were detected. I attempted to combat this by switching from an RGB to HSV color space however there is a lot of room for improvement.
2) Refined Centroid Threshold Using a static centroid threshold during the blob creation vs append step led to a lot of headaches and false positives. Because far away discs are smaller and closer discs are bigger in frame, the static centroid threshold had a tendency to split close discs into multiple blobs. Incorporating a depth sensing modality into the object detection pipeline might be a way to have a dynamic centroid threshold to avoid this problem.
3) Alternative Algorithms Future implementations of object detection will probably incorporate a more elegant detection algorithm; one approach of interest would be k-means clustering. I think that creating a binary mask of the frame based on some threshold may be one approach to combat the specular effects. Once we have this binary mask, k-means clustering becomes a well-suited approach for grouping pixels and determining the blobject centroids.