yolo-scraper
TL;DR
I made a python Reddit scraper that crawls r/WallStreetBets posts using praw and the pushshift.io api (via psaw). The Github repo is located here.
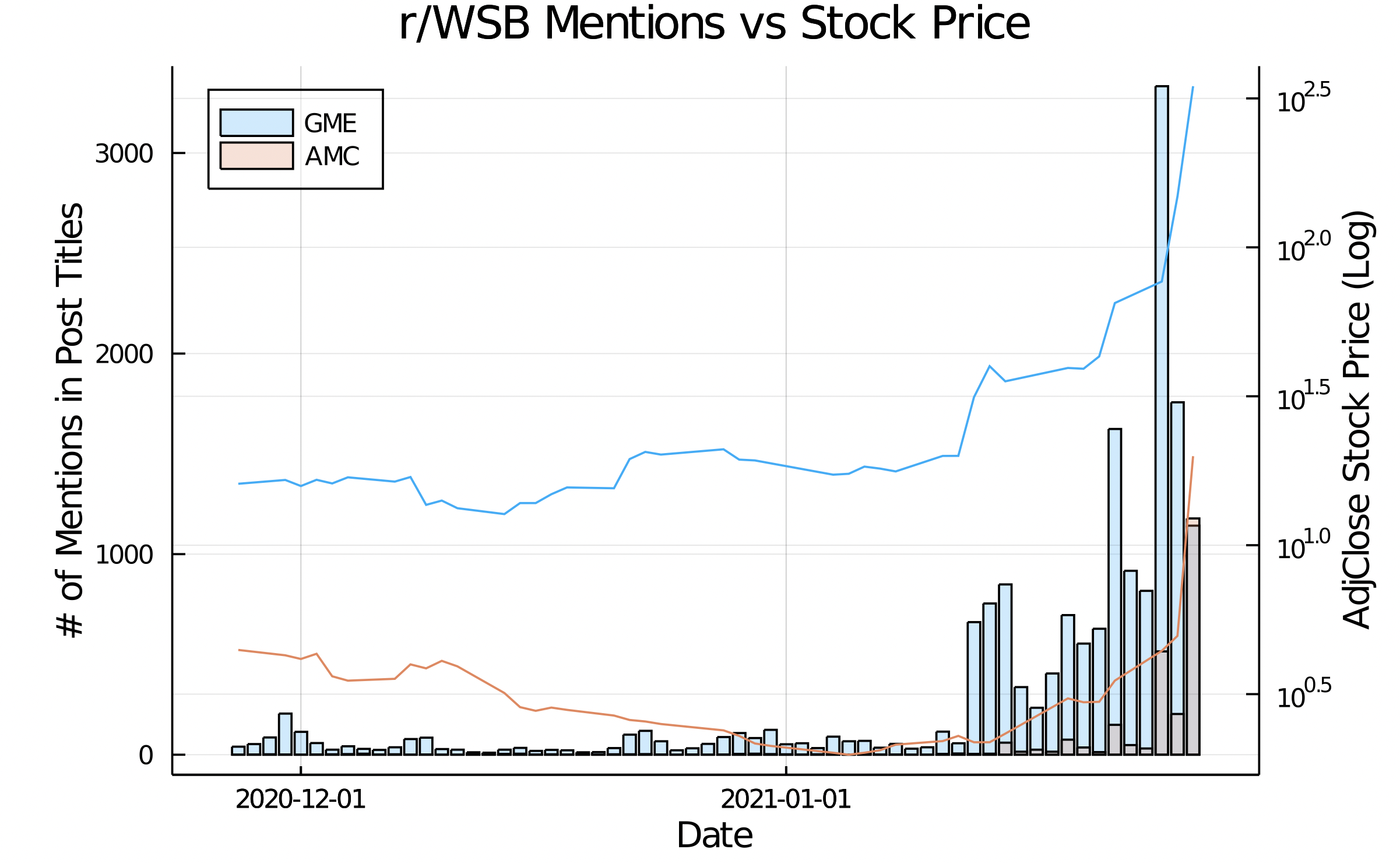
r/WallStreetBets is going totally nuts over $GME. Fundamentals have been thrown out the window and the masses are out for Gabriel Plotkin’s blood. The financial media are losing their minds. Not one to want to miss out on the feeding frenzy but also not one to (totally) blindly hop on the gambling bandwagon, I wanted to collect some data about r/WSB first. Enter yolo-scraper.
The main idea is that we totally ignore market fundamentals and acknowledge that r/WSB is a big rocket-shipyard where lots of stocks are waiting dormant to take off to the moon. Not all rockets will launch and even fewer will reach escape velocity. Instead of being powered through some logical means (profitability, growth potential, etc), these stock valuations are based purely on hype. As more r/WSB denizens hype up the stock, the more it is fueled, and the more likely a moonshot will become. $GME is an excellent example of this:
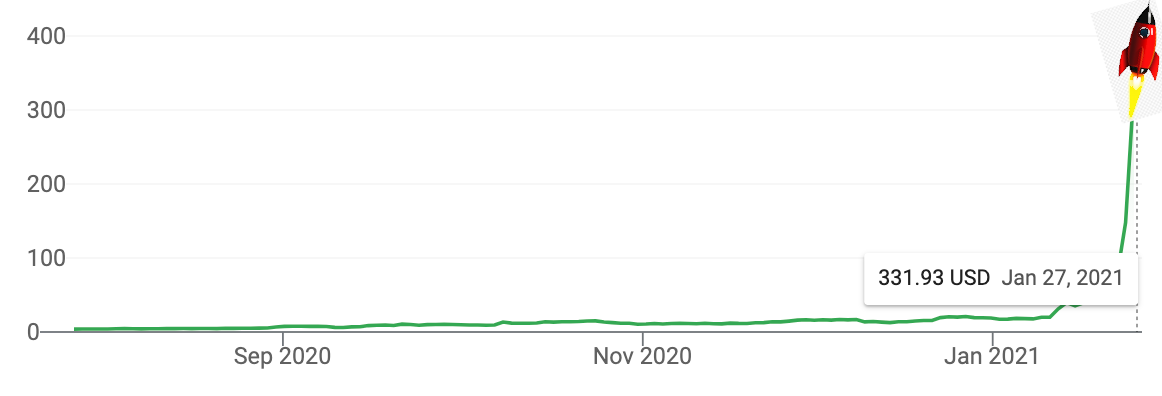
Houston, we have a problem (with efficient-market hypothesis)
If only it was possible to develop some quantitative way to analyze this “hype” fuel and predict whether or not a “stock-rocket” will be a true moonshot. If this was possible, a savvy gambler “investor” could buy early, wait for the rocket to launch, then reap the rewards. This is the though process behind yolo-scraper. The general thought process is:
- Scrape r/WSB to capture time series data about number of mentions of a specific stock symbol.
- Analyze this data for previous trends of “moonshot” stocks
- Attempt to identify “still fueling” stocks before they launch
- ???
- Profit
Scraper Architecture
Turns out Reddit is super easy to scrape and has a really well documented Python API called praw. Unfortunately due to a 2017 change it is really difficult to search posts by date and due to Reddit API constraints, they’ll only return a few (~1000) results to a bulk search. This means that to scrape historical data there is a little bit of legwork since you can’t specify date ranges in the API request.
Luckily a really nice guy put together pushshift.io which is a robust 3rd party database of lots of reddit activity that is sortable by date. Unfortunately for us, they collect posts immediately after submittal so it is difficult to get information on number of upvotes, etc.
In conjunction, we can use the pushshift API to return post ID’s in a specified date range, then make a Reddit API call based on the post ID so we can get relevant statistics on upvotes and similar.
|
|
You’ll notice that we need some credentials. The way that Reddit handles web scraping (and other features such as bots) is that you create an application associated with your user account and then access that app/bot via credentials.
Building the Reddit Bot
This is a very straightforward process that only requires a Reddit account. A lot of these instructions were adapted from/inspired by this post in the footnotes 1.
- Create or login into your Reddit account.
- Navigate to reddit.com/prefs/apps
- Click “create another app…” and select the “script” radio button
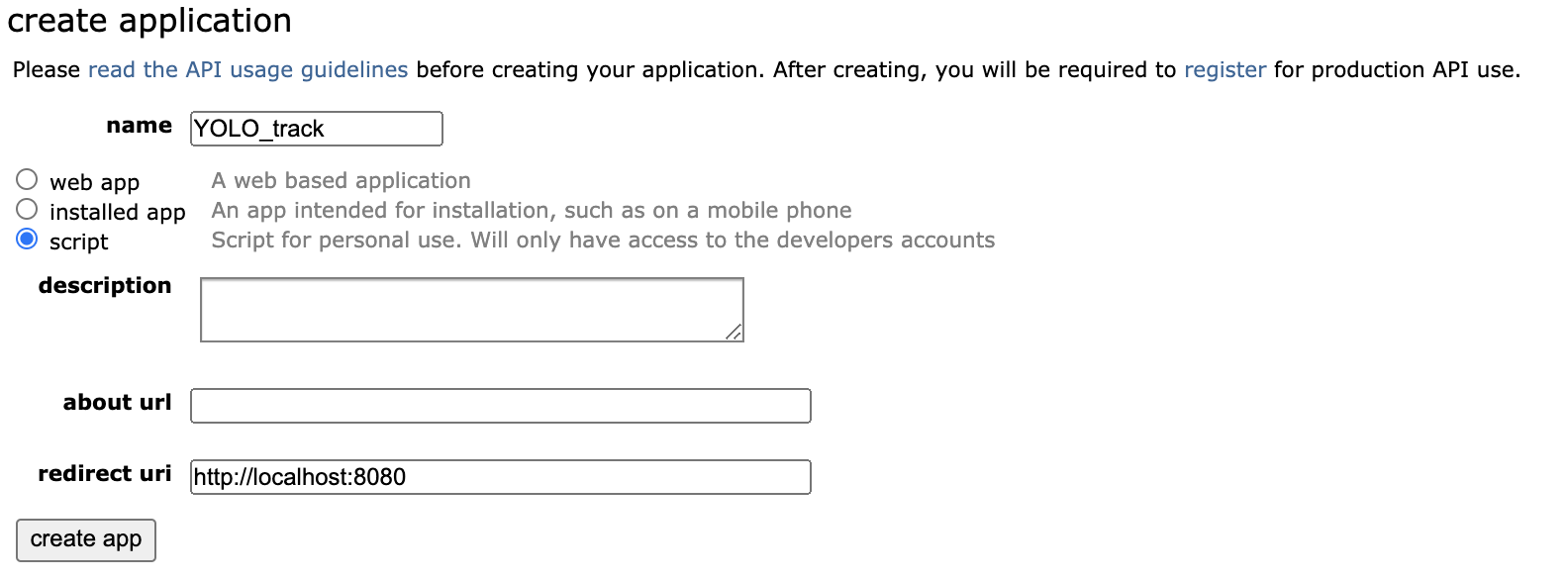
Create an app like this
Get your credentials from the app
config/config.ini file that is read from by yolo-scraper. Instructions on how to do this are in the README of the yolo-scraper repository.
Making an API Call
Now that the credentials are setup, we can access Reddit:
|
|
I did this all in an API class that I built which you can checkout in the Github repo if you care. The big picture is that:
- An API call is made to the PushShift.io API (via
ps_api.search_submissions(...)). This returns a list of post ID’s based on the search parameters. - This list of post ID’s is then sent over in a batch to the Reddit API via
prawand we get up to date information about the posts - sorted by date. - Once this current call to Reddit is done, the results are converted into a pandas dataframe and appended to a csv file.
This process is repeated recursively based on the specified time frame found in the config/config.ini file.
Running the Scraper
Because we need the date search functionality we need to use two API’s. This slows the process down and is coupled with the fact that Reddit API requests are limited to sizes of ~1000 and like 60-120 requests per minute (I’ve seen different numbers online; praw handles this internally I think - I haven’t run into any limits).
As a matter of convenience I am running this script on my Nvidia Jetson Nano since it is easy to SSH into, set, and forget. There is a ton of post history (r/WSB has over 2 million members and growing extremely quickly) so it is a pretty slow process and letting it do it via the Nano is very convenient.

Processing the Data
Used in conjunction with ryssdal.jl, it is possible to compare stock price trends with number of mentions on r/WSB; this is how the plot at the top of the page was created.